PDFファイル(PDF形式)があるの毎日の使用職場やレジャーでの両方の、多くの人々のために。通常、レポート、雑誌、デジタルブック、およびあらゆる種類のドキュメントは、このAdobe形式です。Adobe社のAcrobat Readerアプリケーションは無料で、パソコン、スマートフォンやタブレットにインストールすることができますが、多くの場合、ちょうどそれらを読むことができることは十分ではありません。多くの場合、画像やテキスト、さらにはフォントを抽出できるのは興味深いことです。これを実現するために、アプリケーションまたはオンラインサービスの形で利用できるさまざまなツールがあります。多くは無料です。なか無料ツール、ExtractPDFが際立っています。、それは非常に完全だからです。そのファイル形式からテキスト、フォント、画像を抽出するためだけでなく、関連するメタデータなどの追加情報を抽出することもできます。
ExtractPDFはインターネット上で動作します。ユーザーは2つの方法で操作を実行できます。 1つ目はPDFファイルをサイトにアップロードする方法で、2つ目は処理するファイルがホストされているインターネットアドレス(URL)を入力する方法です。インターフェースは非常にシンプルで、英語とドイツ語の2つの言語で利用できます。使用するために登録する必要はありません。また、電子メールで何らかの確認を行う必要もありません。サービスはアップロードされたファイルのコンテンツにアクセスせず、処理が完了した後にファイルを削除します。
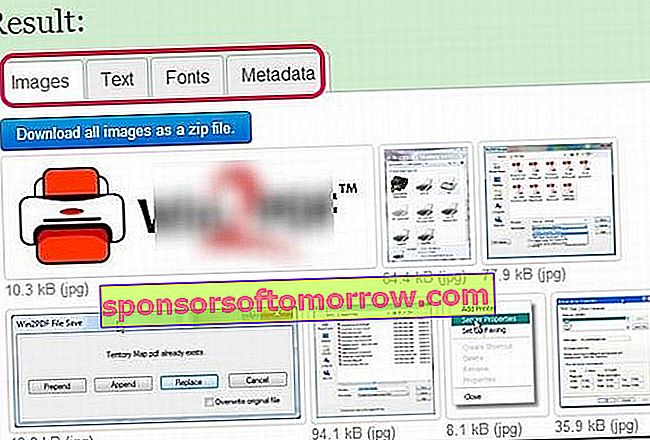
ユーザーがファイルのアップロードを選択した場合、PDFの最大サイズは10 MB(メガバイト)に制限されます。 PDFがアップロードされたら、ユーザーは[ファイルを送信]ボタンをクリックする必要があり、非常に短い時間の後に結果を取得します。プロセスの結果を収集するページには、画像、テキスト、ソース、メタデータの4つのセクションがあります。ユーザーは、コンテンツをダウンロードするために、対応するタブ、たとえば画像付きのタブを選択するだけです。もう1つの利点は、画像やテキストなどがZIPで圧縮されてダウンロードされるため、場所を取らず、操作にほとんど時間がかからないことです。
ExtractPDFツールは、PDFで使用されている元の画像を抽出します。ただし、回転や色反転などのその後の変換は無視してください。フォントに関して、サービスは、抽出されたフォントが元のPDF文書内に表示されるものであることを通知します。つまり、元のファイルに文字「Q」が含まれていない場合、その文字は結果に表示されません。
ExtractPDFサービスは無料で、1日に処理できるファイル数に制限はありません。それは部分的に広告で賄われています。ページに広告を配信します。最後に、Extract PDF Images、PDF Text Extractor、iWeSoft PDF Image Extractorなど、完全ではありませんが無料でもある他の代替ツールがあります。
これは、ExtractPDFサイトへのリンクです。